Artificial Intelligence and Machine Learning
...(incomplete)
What Isn't Covered Here
Timelines for progress made about topics AI, ML
The Presence of Artificial Intelligence on The Media and Social Life
Artificial intelligence is portrayed differently on the media. Sometimes it is changed to create more hype by exaggeration, such manipulations may be done in understandable or actually manipulative levels depending on the depth of focus of honesty of the respective media channel.
AI is even used in politics today. One of the democratic candidates for the 2020 Elections of the United States presidency, Andrew Yang, could be an example for that. Of course his agenda was more complex than that, but to summarize: he would give every American 1000$ a month, for their jobs would be taken over by AI...
Traditional programs vs Self-learning Programs
Conventional/Traditional/Classical programming is mostly about following instructions, but Artificial Intelligence and Machine Learning are more about learning from data.
For self-learning programs, the programmer defines the target, the boundary conditions and the way the program is supposed to learn.
Example: Facial Recognition: For traditional programs, the programmer defines rules, sequences and structures, according to which a person may be defined. Determining these criteria is often quite hard, because not all variations can be considered easily. ML tries to grasp this Uniqueness. The deal with ML is to create a program that could learn all these Uniquenesses. Because that is what us normal people can achieve already. If we already know a person, we can recognize them even if they look slightly different, or even if they've had a surgery.
On self-learning programs, detachment of the expressiveness of what has been learned from individual images is of huge importance.
Conventional Programs
Conventional programs can usually be described using a few if / then rules.
Once the environment has been examined, it can be hardcoded
If there are changes in the environment, the program code must also be changed.
Machine Learning
The concept of learning
The number of all possible combinations is too large to be described by rules.
The working environment can change.
The problem solution is no longer explicitly coded by humans, but there is an artifical intelligence.
Artificial Intelligence
Augmented Intelligence: Augmented intelligence is an alternative conceptualization of artificial intelligence that focuses on the supporting role of AI and emphasizes the fact that cognitive technology is intended to enhance human intelligence rather than replacing it
Weak AI and Strong AI: A weak AI does not have to be inefficient, the term rather refers to the breadth of tasks that the AI can solve. The principle behind the strong AI is that in the future the machines could be made to think or, in other words, represent the human mind.
History of Artificial Intelligence: in 1950 Alan Turing formulated the (classical) Turing Test. It is a test of the ability of a machine to exhibit intelligent behavior that is indistinguishable from that of a human. More on: ddgr -j artificial intelligence milestones
Sub-areas of Artificial Intelligence
Robotics, Machine Learning, Voice recognition, ...
(These topics actually have intersections, and machine larning is even sometimes used as a synonym for AI)
Machine Learning
Machine learning gives computers the ability to learn without being explicitly programmed.
Neural Networks: Special models that are trained on data and can then create good forecasts.
Deep Learning: One speaks of deep learning, if these neural networks have a very large number of layers, whereby they can learn even the most complex issues.
Domain knowledge: Domain knowledge describes the knowledge necessary in the area in which machine learning is to be applied
Sub-Areas Of Machine Learning
The individual paradigms differ, among other things, in the data or in the environment that must exist for them.A supervised learning problem cannot be solved with an unsupervised learning approach.
1. Supervised Learning
E.g. Email validation (Spam or ham(non-spam))If we now build a model that tries to identify the correct category in incoming e-mails, it will often initially be such that the category is guessed. Our model will be learning from the mistakes made along the way
Data Annotation: Data annotation is labeling the available data in various formats such as text, video or images. Supervised machine learning requires labeled data sets so that the machine can understand the input patterns clearly. (e.g. 'car','cyclist', 'pedestrian')
Training Concept of Supervised Learning
How exactly would this training concept look like now, that is, how does the model manage to stop guessing and make a really informed decision based on the email.
2. Unsupervised Learning
In unsupervised learning, a model must look for patterns in a data set with no labels and minimal human supervision. Another name for it is knowledge discovery. Common unsupervised learning techniques include clustering and dimensionality reduction.
3. Semi-supervised Learning
Semi-supervised learning is to a certain extent a combination of supervised learning and unsupervised learning. It is especially useful when we have a lot of data, but only some of it is annotated (Annotation of all of the data may take too much time, or may even be impossible sometimes). We will try to enrich the unannotated data from the information we have from our annotated data. That means to derive there heuristically which category is most likely.
Heuristic: In computer science, a heuristic corresponds to an approach in which an attempt is made to find a suitable solution under "non-optimal" conditions. This does not have to be perfect, but corresponds to a good benefit / cost ratio.
Summary: Part of the database is annotated, another part is not. The non-annotated data are nevertheless used by deriving information on the basis of the annotated data using heuristic methods
Semi-supervised learning is sometimes not considered as a basic paradigm
4. Reinforcement Learning
E.g. bei Hunden
Reinforcement Learning (RL) ist ein Bereich des maschinellen Lernens, in dem es darum geht, wie Software-Agenten in einer Umgebung Maßnahmen ergreifen sollten, um den Begriff der kumulativen Belohnung zu maximieren.
Reinforcement learning (RL) is an area of machine learning that is about how software agents should take action in an environment to maximize the notion of cumulative reward.
Topics that are somehow affiliated with or Used Within AI
These topics could have been opened under other titles above, or under one another. But I thought they'd be more comprehensive if examined separately.
Data Science: CRISP-DM (Cross-industry standard process for data mining)
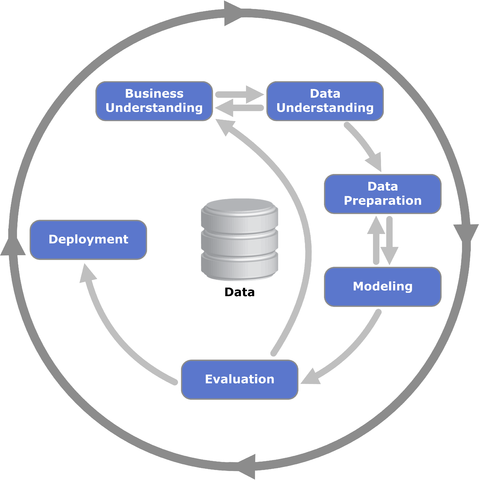
In a data science project the concern is usually the Acquisition, cleansing(preprocessing)-preparation and annotation of data.
It is advised to watch a video like this or that to better understand the above illustrated flow. ( ddgr -j crisp-dm explanation )
Big Data: The emergence of data that cannot be easily processed using conventional methods.Big data is often referred to as the so-called V's, the number of V's admittedly varies regularly.
Volume
Velocity
Variety
Veracity: the uncertainty of the data, i.e. whether the data is reliable or not.
Value
Data Provision: There will be data in numerous different formats and in different scales.
Scales: nominal (green, red, blue), ordinal (There is inner ordering, but no calculations can be done within. e.g. A, B, C (A - B has no meaning)), metric (1, 2, 3)
Ordinal scaled data can sometimes be represented with numbers, but it is sometimes important to ensure that an inner order doesn't come to existance with it (red is not worth more than blue) to achieve that, there are methods like One-Hot Encoding
Word embeddings: Word embeddinh is a learned representation for text where words with the same meaning have a similar representation. This approach to representing words is one of the major breakthroughs in deep learning in challenging NLP (Natural Language Processing) problems. ( E.g. A vector graph where Ankara - Turkey + Germany = Berlin)
Streaming: There's no start or end to the data. e.g. temperature sensors.
Batch processing: A form of data processing in which multiple input jobs are grouped together for processing during the same machine run.
Evaluation Metrics: Evaluation of different ML Models is different depending on the used paradigm.
If a model performs well on the training data but worse on the test data (data should be splitted in such a way beforehand. Test data simulate the data that could come after deployment or during live operation of any sort) this issue should be detected.
Accuracy is not sufficient on its own and can be misleading (the test data may've been easy for the model to tell, and it may've not covered all possibilities equally, etc...). The better alternative would be the Confusion matrix. In the field of machine learning and specifically the problem of statistical classification, a confusion matrix, also known as an error matrix, is a specific table layout that allows visualization of the performance of an algorithm, typically a supervised learning one (in unsupervised learning it is usually called a matching matrix). Each row of the matrix represents the instances in a predicted class while each column represents the instances in an actual class (or vice versa). The name stems from the fact that it makes it easy to see if the system is confusing two classes (i.e. commonly mislabeling one as another).
Precision: What proportion of positive identifications was actually correct?
Recall: What proportion of actual positives was identified correctly?
Generalization, Overfitting and Underfitting: "Generalization is a term used to describe a model’s ability to react to new data. That is, after being trained on a training set, a model can digest new data and make accurate predictions. A model’s ability to generalize is central to the success of a model. If a model has been trained too well on training data, it will be unable to generalize. It will make inaccurate predictions when given new data, making the model useless even though it is able to make accurate predictions for the training data. This is called overfitting. The inverse is also true. Underfitting happens when a model has not been trained enough on the data. In the case of underfitting, it makes the model just as useless and it is not capable of making accurate predictions, even with the training data." (src:
)

This was an into to AI and ML. The following topics will be explained with more detail on their seperate posts:
(to be continued)